Datawarehousing In AWS
Big Data Stack
Project Details
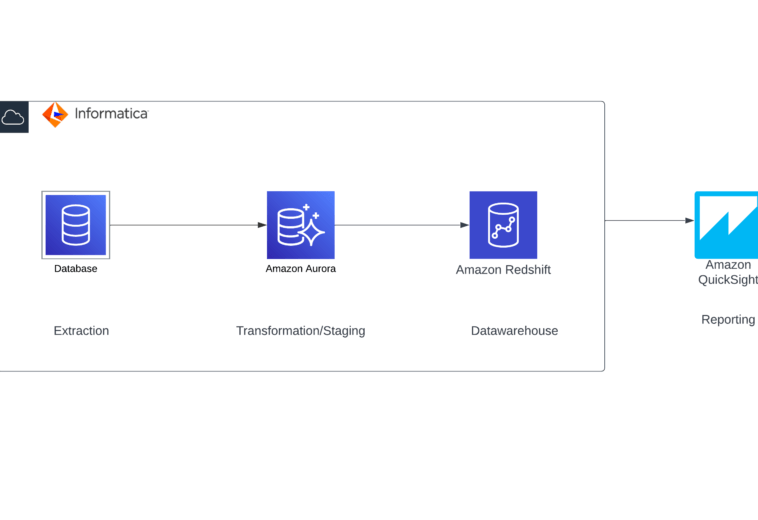
This architecture diagram illustrates a complete end-to-end data processing pipeline, composed of four critical stages: Extract, Transform, Load (ETL), and Reporting. The pipeline is designed to seamlessly pull, process, and present data, making it an essential framework for data engineering workflows.
In this particular design, data is extracted from an organization’s web application, enriched through various transformations, and stored in a data warehouse. Finally, the processed data is visualized in interactive reports for insights. Here’s how it works:
Extract: Data is sourced from the organization’s web application and integrated into the pipeline.
Transform: In a staging environment, the data is cleaned, enriched, and prepared for analysis.
Load: The transformed data is stored in AWS Redshift, a scalable data warehouse solution.
Report: The outcomes are displayed on dynamic dashboards using Amazon QuickSight.
Technology Stack:
AWS EC2: Provides the compute resources to run IICS and store temporary data.
Informatica ELT: Orchestrates data ingestion and stages the data in AWS Aurora.
AWS Redshift: Serves as the primary data warehouse for efficient querying and storage.
Amazon QuickSight: Delivers interactive and visually appealing reports for end-users.
- DATE : 1.3.2021
- CLIENT : Internet Organization
- Skills : Amazon Redshift, Informatica IICS, Amazon Aurora, Datawarehousing, Amazon Quicksight
- Location : Calgary, Alberta